1 2 3 4 5 6 7 8 9 10 simple_grammar =""" sentence => noun_phrase verb_phrase noun_phrase => Article Adj* noun Adj* => null | Adj Adj* verb_phrase => verb noun_phrase Article => 一个 | 这个 noun => 女人 | 篮球 | 桌子 | 小猫 verb => 看着 | 坐着 | 听见 | 看着 Adj => 蓝色的 | 好看的 | 小小的 """
1 2 3 another_grammar = """ # """
1 2 3 def adj () :return random.choice('蓝色的|好看的|小小的' .split('|' ))def adj_star () : return random.choice([lambda : '' ,lambda : adj()+adj_star()])()
'蓝色的好看的小小的好看的小小的蓝色的'
but the question is ? 如果我们更换了语法,会发现所有写过的过程都需要重写
1 2 3 4 adj_grammar =""" Adj* => null | Adj Adj* Adj => 蓝色的 | 好看的 | 小小的 """
1 2 3 4 5 6 7 def create_grammar (grammar_str,split = '=>' ,line_split='\n' ) : grammar = {} for line in grammar_str.split(line_split): if not line.strip(): continue exp,stmt = line.split(split) grammar[exp.strip()]=[s.split() for s in stmt.split('|' )] return grammar
1 grammar=create_grammar(adj_grammar)
[['null'], ['Adj', 'Adj*']]
1 2 3 4 5 6 7 choice = random.choice def generate (gram,target) : if target not in gram: return target expand = [generate(gram,t) for t in choice(gram[target])] return '' .join([e if e != '/n' else '\n' for e in expand if e != 'null' ])
1 example_grammar =create_grammar(simple_grammar)
{'sentence': [['noun_phrase', 'verb_phrase']],
'noun_phrase': [['Article', 'Adj*', 'noun']],
'Adj*': [['null'], ['Adj', 'Adj*']],
'verb_phrase': [['verb', 'noun_phrase']],
'Article': [['一个'], ['这个']],
'noun': [['女人'], ['篮球'], ['桌子'], ['小猫']],
'verb': [['看着'], ['坐着'], ['听见'], ['看着']],
'Adj': [['蓝色的'], ['好看的'], ['小小的']]}
1 generate(gram=example_grammar,target='sentence' )
'这个女人看着一个蓝色的蓝色的好看的桌子'
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 human = """ human = 自己 寻找 活动 自己 = 我 | 俺 | 我们 寻找 = 找找 | 想找点 活动 = 乐子 | 玩的 """ host = """ host = 寒暄 报数 询问 业务相关 结尾 报数 = 我是 数字 号 , 数字 = 单个数字 | 数字 单个数字 单个数字 = 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 寒暄 = 称谓 打招呼 | 打招呼 称谓 = 人称 , 人称 = tb | 神仙 | 傻狗 打招呼 = 你好 | 您好 询问 = 请问你要 | 您需要 业务相关 = 玩玩 具体业务 玩玩 = null 具体业务 = 喝酒 | 打牌 | 打猎 | 赌博 | 踢球 | 飞翔 结尾 = 吗? """
1 2 3 for i in range(20 ): print(generate(create_grammar(human,'=' ),'human' )) print(generate(create_grammar(host,'=' ),'host' ))
我想找点玩的
神仙,您好我是5号,您需要打牌吗?
我们想找点玩的
傻狗,你好我是4号,请问你要踢球吗?
俺想找点玩的
你好我是6号,请问你要打猎吗?
俺找找玩的
你好我是7723号,请问你要打猎吗?
我们想找点玩的
神仙,你好我是2号,您需要打牌吗?
俺找找玩的
神仙,你好我是66号,您需要打牌吗?
我找找玩的
傻狗,您好我是21号,您需要打牌吗?
我们想找点玩的
你好我是6号,您需要飞翔吗?
我们找找玩的
您好我是5号,请问你要打牌吗?
我找找玩的
您好我是9号,请问你要喝酒吗?
俺想找点乐子
你好我是6号,请问你要飞翔吗?
我们想找点玩的
你好我是8号,请问你要飞翔吗?
我找找乐子
您好我是99号,您需要踢球吗?
我想找点乐子
神仙,你好我是95号,您需要飞翔吗?
俺找找玩的
您好我是8号,请问你要飞翔吗?
俺找找乐子
傻狗,你好我是45号,请问你要喝酒吗?
俺找找乐子
您好我是68号,您需要赌博吗?
我们想找点乐子
神仙,你好我是3号,您需要打猎吗?
我们想找点乐子
佟博,您好我是521号,请问你要打猎吗?
我找找乐子
神仙,您好我是2189号,您需要赌博吗?
希望能够生成最合理的一句话? Data Driven 我们的目标是,希望能够在做一个程序,然后,当输入的数据变化的时候,我们的程序不用重写。Generalizatoin.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 simple_programming = """ programming => if_stmt | assign | while_loop while_loop => while ( cond ) { change_line stmt change_line } if_stmt => if ( cond ) { change_line stmt change_line } | if ( cond ) { change_line stmt change_line } else { change_line stmt change_line } change_line => /n cond => var op var op => | == | < | >= | <= stmt => assign | if_stmt assign => var = var var => var _ num | words words => words _ word | word word => name | info | student | lib | database nums => nums num | num num => 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 0 """
1 print(generate(gram=create_grammar(simple_programming,split='=>' ),target='programming' ))
if(lib_name_info>=lib_student){
if(name_2<=name_database){
if(lib<info_lib_database_7){
database=lib_lib
}else{
info_6=info
}
}
}else{
info_0=name_5
}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def pretty_print (line) : lines = line.split('\n' ) code_lines = [] for i , sen in enumerate(lines): if i < len(lines) /2 : code_lines.append(i * " " + sen) else : code_lines.append((len(lines) -i )* " " +sen) return code_lines
1 2 3 4 generated_programming = [] for i in range(20 ): generated_programming += pretty_print(generate(gram=create_grammar(simple_programming,split='=>' ),target='programming' ))
1 2 for line in generated_programming: print(line)
if(student==name){
if(database_student<=lib){
if(student_student_lib_databasename_name){
info=info
}else{
if(info==name){
if(lib<info_3){
if(student_lib_lib_9>=database){
info_6=student_database_lib_lib
}
}
}
}
}
}
while(lib_0<name_name_name_info){
info_lib_database_name=info
}
database_info_database_3=lib_7_5_0_8_5_7_3
database_0=info
while(lib_1_9<=student_lib_student_lib){
if(student_name<info_database_0){
if(database<=student_database){
if(name>=name){
info_info=student_info_lib_name_0
}
}else{
if(lib_database_5_0==name_2){
lib_database_database_4=lib_5
}
}
}else{
info=database_database_database_0
}
}
while(lib_database_lib<=student_6){
if(studentstudent_2){
name_database_7=lib_name_name_7
}else{
if(info_1>=database_4_8){
info=info_1_3_7
}else{
if(name_9_8_9<database){
if(database_info_lib_3_8database_7){
if(name_7>=lib_name_student){
if(student_lib_info_info_2_4_8<lib_6_2_2){
student_lib_database=student_info_3
}else{
info_lib=student_database
}
}
}
}else{
database=lib_student_info_name_student_3_1_7_3
}
}
}
}
if(student>=name_student_database_lib_lib){
name_database_3_4=lib_name_info_info_name_student_info_name
}else{
lib_database=info_lib_student
}
name=name_5_2_3_2_4_5_3_2_0_3_7
info_6=info_student_1
info=lib_9
if(student>=database_2){
name_4_5=student
}
if(student_3_3_6<=name_info_database_8){
if(student_6>=database_student_4){
if(info_2_2_7==info_6_4){
name_8_1=info_student_lib
}else{
database_5=database_1
}
}
}else{
if(lib==database_lib){
lib_0_9_1=lib_0
}else{
if(lib_database>=info_student_0){
student_name_8=name
}else{
if(info_name_lib_name_student_database_lib_name<=student_2){
student_info_0_9_9_1=database
}
}
}
}
while(lib_3_8<=database_0){
if(name_9==lib){
if(lib_name_lib_5info){
if(lib_name_database_3lib_2){
database_info_info=student_1
}
}
}else{
if(name<database_5_1_5_8){
student_student=info
}else{
info_info_7=student_database_database_info_name_1_6
}
}
}
database_database=info_student_database_lib_student
lib=database
student_database_database=name_6
while(student_database<info){
if(info_student_database_student_lib_name_info<=info){
lib_4_5_2=name_info
}else{
lib_2=database_info_name
}
}
while(name_3name_lib){
info=lib
}
while(info_libinfo_4_4_3){
info_name_info_lib_9_9=database_0_4_3
}
if(lib_database_name<student_name_0){
if(name_9_4_4_6student_info_student){
if(name_0lib_1){
lib_lib=database_student_student
}
}else{
if(infostudent){
lib_0=student
}
}
}else{
if(student_name_info_0_9info_lib_9){
database_name_student=name
}else{
if(student<=name){
database=info_info_lib_name_lib_8_7
}else{
if(name_namedatabase_lib_name_8_6){
if(info==name){
info_7_9_5_1_6=info_database
}else{
if(name_student_info_8<=student_database){
info_name_database_database_database=lib_1
}else{
if(name<=info_info_student_student_database_info_lib_lib_info){
student_lib=name_student
}
}
}
}else{
info_6_8_3=info_9_3_7
}
}
}
}
Language Model how to get $ Pr(w_1 |w_2 w_3 w_4)$?
1 2 import randomrandom.choice(range(100 ))
86
1 filename='/Users/24768/sqlResult_1558435.csv'
1 content =pd.read_csv(filename,encoding='gb18030' )
id
author
source
content
feature
title
url
0
89617
NaN
快科技@http://www.kkj.cn/
此外,自本周(6月12日)起,除小米手机6等15款机型外,其余机型已暂停更新发布(含开发版/...
{"type":"科技","site":"cnbeta","commentNum":"37"...
小米MIUI 9首批机型曝光:共计15款
http://www.cnbeta.com/articles/tech/623597.htm
1
89616
NaN
快科技@http://www.kkj.cn/
骁龙835作为唯一通过Windows 10桌面平台认证的ARM处理器,高通强调,不会因为只考...
{"type":"科技","site":"cnbeta","commentNum":"15"...
骁龙835在Windows 10上的性能表现有望改善
http://www.cnbeta.com/articles/tech/623599.htm
2
89615
NaN
快科技@http://www.kkj.cn/
此前的一加3T搭载的是3400mAh电池,DashCharge快充规格为5V/4A。\r\n...
{"type":"科技","site":"cnbeta","commentNum":"18"...
一加手机5细节曝光:3300mAh、充半小时用1天
http://www.cnbeta.com/articles/tech/623601.htm
3
89614
NaN
新华社
这是6月18日在葡萄牙中部大佩德罗冈地区拍摄的被森林大火烧毁的汽车。新华社记者张立云摄\r\n
{"type":"国际新闻","site":"环球","commentNum":"0","j...
葡森林火灾造成至少62人死亡 政府宣布进入紧急状态(组图)
http://world.huanqiu.com/hot/2017-06/10866126....
4
89613
胡淑丽_MN7479
深圳大件事
(原标题:44岁女子跑深圳约会网友被拒,暴雨中裸身奔走……)\r\n@深圳交警微博称:昨日清...
{"type":"新闻","site":"网易热门","commentNum":"978",...
44岁女子约网友被拒暴雨中裸奔 交警为其披衣相随
http://news.163.com/17/0618/00/CN617P3Q0001875...
1 2 articles =content['content' ].tolist() print(articles[:2 ])
['此外,自本周(6月12日)起,除小米手机6等15款机型外,其余机型已暂停更新发布(含开发版/体验版内测,稳定版暂不受影响),以确保工程师可以集中全部精力进行系统优化工作。有人猜测这也是将精力主要用到MIUI 9的研发之中。\r\nMIUI 8去年5月发布,距今已有一年有余,也是时候更新换代了。\r\n当然,关于MIUI 9的确切信息,我们还是等待官方消息。\r\n', '骁龙835作为唯一通过Windows 10桌面平台认证的ARM处理器,高通强调,不会因为只考虑性能而去屏蔽掉小核心。相反,他们正联手微软,找到一种适合桌面平台的、兼顾性能和功耗的完美方案。\r\n报道称,微软已经拿到了一些新的源码,以便Windows 10更好地理解big.little架构。\r\n资料显示,骁龙835作为一款集成了CPU、GPU、基带、蓝牙/Wi-Fi的SoC,比传统的Wintel方案可以节省至少30%的PCB空间。\r\n按计划,今年Q4,华硕、惠普、联想将首发骁龙835 Win10电脑,预计均是二合一形态的产品。\r\n当然,高通骁龙只是个开始,未来也许还能见到三星Exynos、联发科、华为麒麟、小米澎湃等进入Windows 10桌面平台。\r\n']
89611
1 2 3 def token (string) : return re.findall('\w+' ,string)
1 from collections import Counter
1 with_jieba_cut = Counter(jieba.cut(articles[110 ]))
Building prefix dict from the default dictionary ...
Dumping model to file cache C:\Users\24768\AppData\Local\Temp\jieba.cache
Loading model cost 0.957 seconds.
Prefix dict has been built succesfully.
1 with_jieba_cut.most_common()[:10 ]
[(',', 88),
('的', 73),
('。', 39),
('\r\n', 27),
('了', 20),
('们', 18),
('工作队', 16),
('村民', 15),
('收割', 14),
('、', 12)]
1 '' .join(token(articles[110 ]))
'在外国名著麦田里的守望者中作者想要守护麦田里如自己内心一般纯真的孩子们而驻村干部们也在这个炎热的夏天里撸袖子上阵真正做起了村民们的麦田守望者三夏时节不等人你看到了吗不停翻涌起伏仿若铺陈至天边的金黄麦浪中那若隐若现的人影是自治区新闻出版广电局驻和田市肖尔巴格乡合尼村工作队的队员与工作队组织的青年志愿者在这个炎热的夏季他们深入田间地头帮助村民们收割小麦扛起收麦机麦田中的每个人都显得兴致勃勃一天下来就近22亩小麦收割完毕志愿者麦麦提亚森擦去满脸的汗水高兴地告诉驻村队员我们青年志愿者应该多做贡献为村里的脱贫致富出把力工作队带着我们为村里的老人服务看到那些像我爷爷奶奶一样的老人赞许感谢的目光我体会到了帮助他人的快乐自治区新闻出版广电局驻村工作队孙敏艾力依布拉音麦收时节我们在一起6月中旬的和田墨玉麦田金黄静待收割6月14日15日两天自治区高级人民法院驻和田地区墨玉县吐外特乡罕勒克艾日克村工作队与48名村民志愿者一道帮助村里29户有需要的村民进行小麦收割工作田间地头罕勒克艾日克村志愿队的红旗迎风飘扬格外醒目10余台割麦机一起轰鸣男人们在用机器收割小麦的同时几名妇女也加入到志愿队构成了一道美丽的麦收风景休息空闲工作队员和村民们坐在树荫下田埂上互相问好聊天语言交流有困难就用手势动作比划着聊天有趣地交流方式不时引来阵阵欢笑大家在一同享受丰收和喜悦也一同增进着彼此的情感和友谊自治区高级人民法院驻村工作队周春梅艾地艾木阿不拉细看稻菽千重浪6月15日自治区煤田灭火工程局的干部职工们再一次跋涉1000多公里来到了叶城县萨依巴格乡阿亚格欧尔达贝格村见到了自己的亲戚现场处处都透出掩盖不住的喜悦一声声亲切的谢谢一个个结实的拥抱都透露出浓浓的亲情没坐一会儿在嘘寒问暖中大家了解到在麦收的关键时刻部分村民家中却存在收割难的问题小麦成熟期短收获的时间集中天气的变化对小麦最终产量的影响极大如果不能及时收割会有不小损失的于是大家几乎立刻就决定要帮助亲戚们收割麦子在茂密的麦地里干部们每人手持一把镰刀一字排开挽起衣袖卷起裤腿挥舞着镰刀进行着无声的竞赛骄阳似火汗如雨下但这都挡不住大家的热情随着此起彼伏的镰刀割倒麦子的刷刷声响不一会一束束沉甸甸的麦穗就被整齐地堆放了起来当看到自己亲手收割的金黄色麦穗被一簇簇地打成捆运送到晒场每个人的脸上都露出了灿烂的笑容自治区煤田灭火工程局驻村工作队马浩南这是一个收获多多的季节6月13日清晨6时许和田地区民丰县若雅乡特开墩村的麦田里已经传来马达轰鸣声原来是自治区质监局驻村工作队趁着天气尚且凉爽开始了麦田的收割工作忙碌间隙志愿者队伍搬来清凉的水村民们拎来鲜甜的西瓜抹一把汗水吃一牙西瓜甜蜜的汁水似乎流进了每一个人的心里说起割麦子对于生活在这片土地上的村民来说是再平常不过的事但是对于工作队队员们来说却是陌生的自治区质监局驻民丰县若克雅乡博斯坦村工作队队员们一开始觉得十几个人一起收割二亩地应该会挺快的结果却一点不简单镰刀拿到自己手里割起来考验才真正的开始大家弓着腰弯着腿亦步亦趋手上挥舞着镰刀时刻注意不要让镰刀割到自己脚下还要留心不要把套种的玉米苗踩伤不一会儿就已经汗流浃背了抬头看看身边的村民早就远远地割到前面去了只有今年已经56岁的工作队队长李树刚有割麦经验多少给队员们挽回了些面子赶不上村民们割麦子的速度更不要说搞定收割机这台大家伙了现代化的机械收割能成倍提升小麦的收割速度李树刚说不过能有这样的体验拉近和村民的距离也是很难得的体验自治区质监局驻村工作队王辉马君刚我们是麦田的守护者为了应对麦收新疆银监局驻和田县塔瓦库勒乡也先巴扎村工作队一早就从经济支援和人力支援两方面做好了准备一方面工作队帮村里购入了5台小麦收割机另一边还组织村干部青年团员等组成了6支近百人的收割先锋突击队帮助村民们抢收麦子看着及时归仓的麦子村民们喜得合不拢嘴纷纷摘下自家杏树上的杏子送给工作队金黄的麦穗温暖了村民们的心香甜的杏子温暖了工作队员的心麦子加杏子拉近了村民和队员们的心新疆银监局驻村工作队王继发免责声明本文仅代表作者个人观点与环球网无关其原创性以及文中陈述文字和内容未经本站证实对本文以及其中全部或者部分内容文字的真实性完整性及时性本站不作任何保证或承诺请读者仅作参考并请自行核实相关内容'
1 articles_clean = ['' .join(token(str(a))) for a in articles]
89611
1 2 3 with open('article_tb.txt' ,'w' ) as f: for a in articles_clean: f.write(a + '\n' )
1 def cut (string) :return list(jieba.cut(string))
1 2 3 4 for i, line in enumerate((open('article_tb.txt' ))): if i%100 ==0 : print(i) if i >100000 :break TOKEN.extend(cut(line))
0
100
200
300
400
500
600
700
800
900
1000
1100
1200
1300
1400
1500
1600
1700
1800
1900
2000
2100
2200
2300
2400
2500
2600
2700
2800
2900
3000
3100
3200
3300
3400
3500
3600
3700
3800
3900
4000
4100
4200
4300
4400
4500
4600
4700
4800
4900
5000
5100
5200
5300
5400
5500
5600
5700
5800
5900
6000
6100
6200
6300
6400
6500
6600
6700
6800
6900
7000
7100
7200
7300
7400
7500
7600
7700
7800
7900
8000
8100
8200
8300
8400
8500
8600
8700
8800
8900
9000
9100
9200
9300
9400
9500
9600
9700
9800
9900
10000
10100
10200
10300
10400
10500
10600
10700
10800
10900
11000
11100
11200
11300
11400
11500
11600
11700
11800
11900
12000
12100
12200
12300
12400
12500
12600
12700
12800
12900
13000
13100
13200
13300
13400
13500
13600
13700
13800
13900
14000
14100
14200
14300
14400
14500
14600
14700
14800
14900
15000
15100
15200
15300
15400
15500
15600
15700
15800
15900
16000
16100
16200
16300
16400
16500
16600
16700
16800
16900
17000
17100
17200
17300
17400
17500
17600
17700
17800
17900
18000
18100
18200
18300
18400
18500
18600
18700
18800
18900
19000
19100
19200
19300
19400
19500
19600
19700
19800
19900
20000
20100
20200
20300
20400
20500
20600
20700
20800
20900
21000
21100
21200
21300
21400
21500
21600
21700
21800
21900
22000
22100
22200
22300
22400
22500
22600
22700
22800
22900
23000
23100
23200
23300
23400
23500
23600
23700
23800
23900
24000
24100
24200
24300
24400
24500
24600
24700
24800
24900
25000
25100
25200
25300
25400
25500
25600
25700
25800
25900
26000
26100
26200
26300
26400
26500
26600
26700
26800
26900
27000
27100
27200
27300
27400
27500
27600
27700
27800
27900
28000
28100
28200
28300
28400
28500
28600
28700
28800
28900
29000
29100
29200
29300
29400
29500
29600
29700
29800
29900
30000
30100
30200
30300
30400
30500
30600
30700
30800
30900
31000
31100
31200
31300
31400
31500
31600
31700
31800
31900
32000
32100
32200
32300
32400
32500
32600
32700
32800
32900
33000
33100
33200
33300
33400
33500
33600
33700
33800
33900
34000
34100
34200
34300
34400
34500
34600
34700
34800
34900
35000
35100
35200
35300
35400
35500
35600
35700
35800
35900
36000
36100
36200
36300
36400
36500
36600
36700
36800
36900
37000
37100
37200
37300
37400
37500
37600
37700
37800
37900
38000
38100
38200
38300
38400
38500
38600
38700
38800
38900
39000
39100
39200
39300
39400
39500
39600
39700
39800
39900
40000
40100
40200
40300
40400
40500
40600
40700
40800
40900
41000
41100
41200
41300
41400
41500
41600
41700
41800
41900
42000
42100
42200
42300
42400
42500
42600
42700
42800
42900
43000
43100
43200
43300
43400
43500
43600
43700
43800
43900
44000
44100
44200
44300
44400
44500
44600
44700
44800
44900
45000
45100
45200
45300
45400
45500
45600
45700
45800
45900
46000
46100
46200
46300
46400
46500
46600
46700
46800
46900
47000
47100
47200
47300
47400
47500
47600
47700
47800
47900
48000
48100
48200
48300
48400
48500
48600
48700
48800
48900
49000
49100
49200
49300
49400
49500
49600
49700
49800
49900
50000
50100
50200
50300
50400
50500
50600
50700
50800
50900
51000
51100
51200
51300
51400
51500
51600
51700
51800
51900
52000
52100
52200
52300
52400
52500
52600
52700
52800
52900
53000
53100
53200
53300
53400
53500
53600
53700
53800
53900
54000
54100
54200
54300
54400
54500
54600
54700
54800
54900
55000
55100
55200
55300
55400
55500
55600
55700
55800
55900
56000
56100
56200
56300
56400
56500
56600
56700
56800
56900
57000
57100
57200
57300
57400
57500
57600
57700
57800
57900
58000
58100
58200
58300
58400
58500
58600
58700
58800
58900
59000
59100
59200
59300
59400
59500
59600
59700
59800
59900
60000
60100
60200
60300
60400
60500
60600
60700
60800
60900
61000
61100
61200
61300
61400
61500
61600
61700
61800
61900
62000
62100
62200
62300
62400
62500
62600
62700
62800
62900
63000
63100
63200
63300
63400
63500
63600
63700
63800
63900
64000
64100
64200
64300
64400
64500
64600
64700
64800
64900
65000
65100
65200
65300
65400
65500
65600
65700
65800
65900
66000
66100
66200
66300
66400
66500
66600
66700
66800
66900
67000
67100
67200
67300
67400
67500
67600
67700
67800
67900
68000
68100
68200
68300
68400
68500
68600
68700
68800
68900
69000
69100
69200
69300
69400
69500
69600
69700
69800
69900
70000
70100
70200
70300
70400
70500
70600
70700
70800
70900
71000
71100
71200
71300
71400
71500
71600
71700
71800
71900
72000
72100
72200
72300
72400
72500
72600
72700
72800
72900
73000
73100
73200
73300
73400
73500
73600
73700
73800
73900
74000
74100
74200
74300
74400
74500
74600
74700
74800
74900
75000
75100
75200
75300
75400
75500
75600
75700
75800
75900
76000
76100
76200
76300
76400
76500
76600
76700
76800
76900
77000
77100
77200
77300
77400
77500
77600
77700
77800
77900
78000
78100
78200
78300
78400
78500
78600
78700
78800
78900
79000
79100
79200
79300
79400
79500
79600
79700
79800
79900
80000
80100
80200
80300
80400
80500
80600
80700
80800
80900
81000
81100
81200
81300
81400
81500
81600
81700
81800
81900
82000
82100
82200
82300
82400
82500
82600
82700
82800
82900
83000
83100
83200
83300
83400
83500
83600
83700
83800
83900
84000
84100
84200
84300
84400
84500
84600
84700
84800
84900
85000
85100
85200
85300
85400
85500
85600
85700
85800
85900
86000
86100
86200
86300
86400
86500
86600
86700
86800
86900
87000
87100
87200
87300
87400
87500
87600
87700
87800
87900
88000
88100
88200
88300
88400
88500
88600
88700
88800
88900
89000
89100
89200
89300
89400
89500
89600
1 from functools import reduce
1 from operator import add,mul
1 reduce(add,[1 ,2 ,3 ,4 ,5 ,8 ])
23
1 words_count =Counter(TOKEN)
1 words_count.most_common(100 )
[('的', 703716),
('n', 382020),
('在', 263597),
('月', 189330),
('日', 166300),
('新华社', 142462),
('和', 134061),
('年', 123106),
('了', 121938),
('是', 100909),
('\n', 89611),
('1', 88187),
('0', 84945),
('外代', 83268),
('中', 73926),
('中国', 71179),
('2', 70521),
('2017', 69894),
('记者', 62147),
('二线', 61998),
('将', 61420),
('与', 58309),
('等', 58162),
('为', 57019),
('5', 54578),
('照片', 52271),
('4', 51626),
('对', 50317),
('上', 47452),
('也', 47401),
('有', 45767),
('5', 40857),
('说', 39017),
('发展', 37632),
('他', 37194),
('3', 36906),
('以', 36867),
('国际', 35842),
('nn', 35330),
('4', 34659),
('比赛', 32232),
('6', 30575),
('到', 30109),
('人', 29572),
('从', 29489),
('6', 29002),
('都', 28027),
('不', 27963),
('后', 27393),
('当日', 27186),
('就', 26684),
('并', 26568),
('国家', 26439),
('7', 26386),
('企业', 26147),
('进行', 25987),
('3', 25491),
('美国', 25485),
('举行', 25389),
('被', 25277),
('北京', 25245),
('体育', 24873),
('2', 24376),
('1', 24182),
('这', 24118),
('新', 23828),
('但', 23385),
('比', 23229),
('个', 23081),
('足球', 22554),
('表示', 22134),
('经济', 22006),
('我', 21940),
('一个', 21932),
('9', 21920),
('还', 21861),
('合作', 21567),
('要', 21045),
('n5', 20946),
('已', 20882),
('摄', 20837),
('8', 20701),
('工作', 20700),
('n4', 20658),
('选手', 19986),
('我们', 19982),
('市场', 19001),
('一路', 18978),
('一带', 18907),
('建设', 18634),
('让', 18609),
('日电', 18384),
('通过', 18159),
('多', 17760),
('时', 17750),
('完', 17424),
('于', 17421),
('问题', 17338),
('更', 17275),
('项目', 17260)]
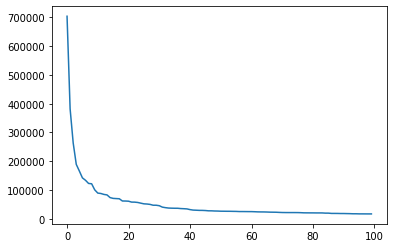
1 frequiences = [f for w,f in words_count.most_common(100 )]
1 x =[ i for i in range(100 )]
1 import matplotlib.pyplot as plt
[<matplotlib.lines.Line2D at 0x16f678b8b48>]
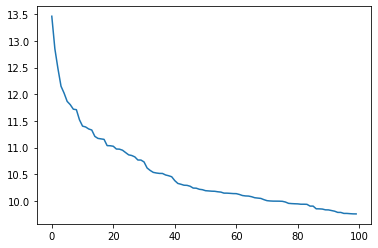
NLP比较重要的规律,在很大的一个 text corpus, 文字集合中,出现频率第二多的单词,是出现频率第一多单词频率的1/2,出现频率滴N多的的单词是第一多的1/N
1 plt.plot(x,np.log(frequiences))
[<matplotlib.lines.Line2D at 0x16efa34bf08>]
1 2 def prob_1 (word) : return words_count[word] / len(TOKEN)
0.0011341645999654677
1 2 TOKEN[:10 ] len(TOKEN[:-1 ])
17618253
1 TOKEN = [str(t) for t in TOKEN]
1 2 TOKEN_2_GRAM = ['' .join(TOKEN[i:i+2 ]) for i in range(len(TOKEN[:-2 ]))] len(TOKEN[:-2 ])
17618252
['此外自', '自本周', '本周6', '6月', '月12', '12日起', '日起除', '除小米', '小米手机', '手机6']
1 words_count_2 =Counter(TOKEN_2_GRAM)
1 2 3 4 def prob_2 (word1,word2) : if word1+word2 in words_count_2: return words_count_2[word1+word2] / len(TOKEN_2_GRAM) else : return 1 / len(TOKEN_2_GRAM)
3.0536514065072974e-05
7.946304775297799e-07
1 2 3 4 5 6 7 8 9 def get_probablity (sentence) : words = cut(sentence) sentence_prob =1 for i , word in enumerate(words[:-1 ]): next_ =words[i+1 ] probablity =prob_2(word,next_) sentence_prob *= probablity sentence_prob*=prob_1(word[-1 ]) return sentence_prob
1 get_probablity('fd是一个小可爱' )
5.193529218987722e-22
1 get_probablity('小敏今天抽到了一个iphone' )
9.08660601226132e-36
1 2 for sen in [generate(gram=example_grammar,target='sentence' ) for i in range(10 )]: print('sentence: {} with Prb: {}' .format(sen,get_probablity(sen)))
sentence: 一个好看的小猫坐着一个小猫 with Prb: 3.288492351824868e-47
sentence: 这个蓝色的小小的好看的女人看着一个好看的蓝色的好看的小猫 with Prb: 1.4336960791945416e-97
sentence: 一个桌子看着这个篮球 with Prb: 1.6316301805544588e-31
sentence: 一个小小的蓝色的好看的小猫听见一个小猫 with Prb: 5.413402114895177e-62
sentence: 这个女人听见一个女人 with Prb: 4.894890541663377e-31
sentence: 这个好看的小小的女人看着这个好看的篮球 with Prb: 7.764808720237364e-62
sentence: 这个桌子看着一个好看的篮球 with Prb: 2.948877435423709e-42
sentence: 这个小小的好看的篮球看着这个小小的小小的小小的小猫 with Prb: 1.4874477576323182e-68
sentence: 这个篮球坐着一个好看的好看的桌子 with Prb: 4.8451281079684025e-59
sentence: 这个女人听见这个好看的篮球 with Prb: 2.948877435423709e-42
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 need_compared = [ "今天晚上请你吃饭,我们一起吃火锅 明天晚上请你吃饭,我们一起吃烧烤" , "真实一只可爱的小猫 真是一只可爱的小猫" , "今天晚上去飞翔 今天晚上飞翔去我" , "洋葱奶昔来一杯 养乐多绿来一杯" ] for s in need_compared: s1,s2 =s.split() p1,p2 = get_probablity(s1),get_probablity(s2) better = s1 if p1 > p2 else s2 print('{} is more possible' .format(better)) print('-' *4 + ' {} with probablity {}' .format(s1,p1)) print('-' *4 + ' {} with probablity {}' .format(s2,p2))
今天晚上请你吃饭,我们一起吃火锅 is more possible
---- 今天晚上请你吃饭,我们一起吃火锅 with probablity 6.195089781185323e-58
---- 明天晚上请你吃饭,我们一起吃烧烤 with probablity 4.512004197519248e-64
真是一只可爱的小猫 is more possible
---- 真实一只可爱的小猫 with probablity 5.014470336000062e-27
---- 真是一只可爱的小猫 with probablity 5.014470336000062e-27
今天晚上去飞翔 is more possible
---- 今天晚上去飞翔 with probablity 1.1061245254231737e-24
---- 今天晚上飞翔去我 with probablity 2.3020387757829988e-31
养乐多绿来一杯 is more possible
---- 洋葱奶昔来一杯 with probablity 1.1160363145085983e-25
---- 养乐多绿来一杯 with probablity 1.9662609030163744e-18
Data Driven 假如你做了很久的数据预处理 AI的问题里边,65%都在做数据预处理 我们养成一个习惯,把数据存到硬盘里